Tac-Valuer: Knowledge-based Stroke Evaluation in Table Tennis
Tac-Valuer: Knowledge-based Stroke Evaluation in Table Tennis(KDD2021)を読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
背景と概要
背景
課題
- コーチが卓球の試合で選手のパフォーマンスを見る上で、ストロークの評価は非常に重要。
- ストローク:打法、スイング
- ただし、現在の方法では熟練した知識が要求される上に時間もかかる。
- 卓球の評価方法は以下の2つに分けられている
考えられる施策
ナショナルチームとの共同研究

概要
- 卓球のアナリストのための自動ストローク評価フレームワークTac-Valureを提案。
- 今回のようなタスクの場合、アナリストの知識と機械学習モデルの組み合わせ方が課題となる。
- アナリストの知識を機械学習モデルに統合するために、abductive learning(ABL)に基づいた方法(computer visionアルゴリズムと知識に基づいたルールベースのロジックを組み合わせ)ストロークに関する特徴量の埋め込みをおこなった。
- 使用データ:卓球中国代表選手のもの
Tac-Valueのステップ
- 以下3ステップで構成
- video formalizing(VF):動画の形式化
- stroke embedding (SE):stroke埋め込み
- ここで属性を学習strokeし、中間層の特徴量を抽出しstroke embeddingとする。
- component
- 属性認識component:ニューラルネットワークを利用
- 論理的推論component:ルールベースを利用
- ラベルの無いデータに対しても、上記componentを利用し学習を行う。
- performance rating (PR):性能評価
- SEを入力として、strokeのパフォーマンスをDeep forestで予測
活用の仕方
各試合におけるstrokeテクニック毎のパフォーマンスやラリー毎のパフォーマンスを定量化する事で、なぜ試合に勝った(or負けた)のかを考察しやすくする。
[以下長い詳細]
Data
必要なデータ
- Tac-Valuerでは学習のために4つのデータが必要となる。
- stroke videos:Tac-Valuerの入力
- stroke属性:SE(stroke embedding)用学習ラベル
- 推論ルール:アナリストの知識の定量化
- パフォーマンススコア:PR(Performance Rating)で利用
stroke videos
- 各stroke videoは、8つのフレームシーケンスで構成
- プレイヤーがボールに触れた時の中央のフレーム
- その前の4フレーム
- 中央の後の3フレーム
ラベリングに熟練の知識はいらないので、クラウドソーシングで、21試合から9,522本のストロークを収集。
stroke属性
このデータは、SEのモデルを学習するトレーニングラベルとして使用。
stroke属性のラベリングには卓球の知識が必要となるため、アナリストがデータ収集を行っている。
- 以下図にstroke属性のデータ例が示されている。
- 最初の3属性:試合の中のstrokeの時間的な位置を特定する
- 続く3属性:strokeの技術的特徴
- stroke technique
- stroke position:ボールを打つ時のプレイヤーのポジション
- stroke placement:打つ前のボールの位置
- 最後の属性:Striker, strike time()

推論ルール(ルールベース)
データ収集時のアナリストの知識をまとめ、以下の形で定量化。 以下の例では、前のstrokeが「Block」の場合、現在のstrokeが「Push」「Short」「Slide」「Block」になる事が出来ない事を意味している。 今回は28個のルールを作っている。
パフォーマンススコア
このスコアはPR(Performance Rating)モデルの学習用ラベルとして使われる。
- プロのアナリストが手動で評価した
- 有利なstroke:1、不利なstroke:-1
アノテーションの仕方
- 全部で7人が評価
- 各strokeは3人のアナリストで評価し、多数決
- 3人のアナリストの評価が異なる場合→別のシニアアナリストが再評価
Tac-Valuerのフレームワーク
問題定義
卓球では、双方のプレイヤーが交互にストロークをやりとりする。
今回はFを構築する際に、アナリストの評価プロセスを模倣している。
- 一般にアナリストはstroke属性に加えその動きも考慮する必要がある。
- 以下画像のような場合、これらのstrokeの効果は明らかに異なるが、属性だけ見ると似たようなstrokeになる。
- そのため、動きまで含めると十分な情報を得られる事となる。

Tac-Valuer構築時の課題
- いかにして映像のノイズを減らすか
- stroke映像では、以下のように主にコート上の審判等の選手以外の人物がノイズとなり、アルゴリズムの精度を下げる要因となる。

限られたラベル付きデータでstrokeの特徴を効果的に抽出・埋め込みを行うには
- ラベル付きデータを作るには熟練したドメイン知識が必要となるため、作れる量に限界がある。
- strokeの動きをどう評価するかはまだあまり研究されていない。
strokeのパフォーマンスをどう定量化するか
Tac-Valuerのフレームワーク構成
以下図のような3ステップの構成となる。
- video formalizing (VF):ビデオフレーム内の無関係な人物の削除
- object detection algorithmでプレイヤーを検出、無関係な人物をマスクする
- stroke embedding (SE):ABLを活用し、stroke属性を抽出し動きと合わせて埋め込み。
- 属性を認識するcomponentを使用し、strokeを特徴ベクトルに埋め込み。
- 推論component(ルールベース)を使ってラベル無しデータの疑似ラベルを改善。
- 上記を繰り返す。
- performance rating (PR):分類器により評価結果を取得
- ステップ2の埋め込みベクトルを用いて、各strokeのレベルを分類するモデルを学習。

video formalizing (VF):上図A
- VFは以下の流れとなっている
- Faster-RCNNで各フレームのテーブルと全人物のbounding boxを検出。
- テーブルのboxと人物のboxの位置関係から2人のプレイヤーを特定。
- 他の人物はマスクする。
Stroke embedding(SE):上図B
ここでは動画フレームから特徴ベクトルへの埋め込みを行う。
- ステップは以下画像のように2つに分けられる
- 属性認識component(A)
- 論理的abduction component(B)
属性認識component
- 本componentでは、以下の構成となる。
本componentはラベル付きstroke動画で事前学習されるので、ラベル無しの動画では誤った疑似ラベルを生成し得る。
論理的abduction component
- 本componentは以下のプロセスとなる
- 疑似ラベルがルールと一致するかをチェック。
- 一致していればそのまま返し、そうでなければ推論ルールを用いて疑似ラベルを修正する。
最後に、修正された疑似ラベルはground-truthラベルとして扱われ、属性認識componentに戻り学習される。 このサイクルを繰り返す。
Performance rating(PR)
Stroke embeddingで生成した特徴ベクトルをDF21(Deep Forest)で学習させる。
Evaluation
SE部分の検証
- 3パターンの手法でテクニック(tec)・位置(pla)・配置(pos)・ストライカー(striker)がどちらかを検証
- 配置に関しては提案手法が最もパフォーマンスが高く、他の指標は50%教師ありを超えたと主張。

PR部分の検証
Deep Forest以外にGBDT系、ランダムフォレスト等で検証しDeep Forestが最も精度が良かったと述べている。

実際のUse Cases
中国の卓球選手に対して強敵である伊藤美誠選手の分析がされている。
Ito should reduce errors in matches
以下の図が、2019年ITTFワールドツアーの女子シングルス決勝、準決勝、準々決勝で伊藤選手(紫)とChen Meng選手、Sun Yingsha選手、Wang Manyu選手(それぞれのオレンジ)が対戦したもの。
A:それぞれのstrokeテクニック毎のパフォーマンスを表したもの(積算)。プラスに振れている方が良いパフォーマンスとなる。
- Sun選手とWang選手と対戦した際に、伊藤選手のパフォーマンスが優れている。
- Wang選手との場合には、特にPush,Shortが相対的に優れている。
- ただChen選手と試合した際には、あまり優位性を発揮できていなかった。
- Sun選手とWang選手と対戦した際に、伊藤選手のパフォーマンスが優れている。
B:Chen選手と試合した際のラリー毎のstrokeパフォーマンスを更に検証したもの。
- 棒グラフの高さ:パフォーマンスの差の絶対値
- オレンジが上に伸びていれば、Chen選手の当該ラリーのstrokeのパフォーマンスが高い事を示す。
- 中心の点:各ラリーでどちらが点を取ったかを示す。
- 棒グラフの高さ:パフォーマンスの差の絶対値
本論文では、Cで囲ってある領域のように伊藤選手が非常に高いパフォーマンスを発揮したラリーで得点を落とさない事が必要だと述べていた。
[感想]全体的にパフォーマンスを見ると、安定して相対的に高いパフォーマンスのラリーを行う事が勝つ事に繋がってそうに見えた。

参考文献
https://dl.acm.org/doi/10.1145/3447548.3467104 http://129.211.169.156/publication/kdd21Tac_Valuer.pdf
Exploratory Machine Learning with Unknown Unknowns
Exploratory Machine Learning with Unknown Unknowns
(AAAI2021 accepted paperのarxiv版)を読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
背景と概要
概要
- 従来の教師あり学習では、学習データに既知のラベルセットからの正解が与えられ、学習したモデルは未知のデータに対してラベルをつける。
- 論文では、学習データセットに間違ったラベルが振られた未知のクラス(unknown unknowns)が存在し、教師データからは真のラベルがわからない問題設定を考える。
- なぜこのような事が起きるか:特徴情報が不足していることに依り、ラベル空間が不完全に認識されるために発生すると考えられる。
- 真のラベル空間:ground-truth label space
- 環境・条件等により不完全なラベル空間:known label space
- なぜこのような事が起きるか:特徴情報が不足していることに依り、ラベル空間が不完全に認識されるために発生すると考えられる。
- 対策:特徴空間を積極的に拡張する事で未知のラベルを発見する探索的機械学習(exploratory machine learning:ExML)を提案。
unknown unknownsが発生するような場面
- 以下図のような医療診断のタスクを考える。
- そのため、学習モデルでは未知のクラスの発見と既知のクラスの分類を同時に行う必要がある。

ExML: A New Learning Framework
Exploratory Machine Learning
- 本項において、探索的機械学習(ExML)を紹介する
- 特徴量不足によるunknown unknownsを処理するために、the human in the learning loopを活用する。
- もう少し掘り下げると、潜在する未知のクラスを発見し既存のクラスを分類する事行うために、learner:学習者(人)が学習データセットを調べ、調査(新しい特徴量情報を探索)を行う
- 具体例としては以下のような事があげられている。
- 学習モデルが多くのデータを与えてもパフォーマンスが低い場合、learnerが未知のクラスの存在を疑い特徴の補強を行う。
- 概要は以下図であり、learnerが分類性の悪い2つのクラスに気づき適切な特徴の増強を行った結果、未知の追加クラスが存在する事に気づく。

既存の教師あり学習との比較
従来の教師あり学習(SL)では、学習データセットを環境の観測可能な表現とみなし、それを予測するためモデルを学習するとしている。(個人的には納得したような、しないような気持)
ExMLでは、学習データセットを操作可能なものと考え、learnerが多くの特徴量情報を探索する事により、特徴量の不足によるunknown unknownsを発見できると考える。

Problem Formulation
学習とテストにおいて以下のように問題設定がされている。
Training Dataset
Candidate Features and Cost Budget(候補特徴量とコスト予算)
learnerは学習セット以外に候補特徴量 (取得前は未知)にアクセスできるとする。
本候補特徴量は、医療診断の例で言うと患者が検査後に得られるCTスキャンの信号等になる。
- 以下の様な条件を考える
- どのサンプルでも、候補特徴量を取得する場合一定のコストがかかる。
- learnerは与えられた予算Bの中で、上位k個の有益な特徴を活用する事を目的とする。
- 簡単のために各特徴量の取得コストは1とする。(特徴量毎の取得するためのコストの違いは考慮してない)
Testing Stage
Learnerが最適な候補特徴量をと決定したとすると、learnerはこの特徴量でテストサンプルを拡張する。
学習モデルは拡張されたテストサンプルのラベルを予測し、既知のクラスのどれかに分類するか未知のクラス(uc)に分類される。
実用的なアプローチ
- 今回、以下の3つの構成要素からなるアプローチが設計されている。(概要は以下図)
- rejection model(拒絶モデル)
- feature acquisition(特徴取得)
- model cascade

Rejection model
上図にあるように、learnerは最初に自身の無いinstanceを疑わしいと識別する能力をオリジナルのデータセットで学習する必要がある。
ここでは、条件付確率の最大値が1-θ(0<θ<0.5)の閾値より低いインスタンスの予測を行わない「拒絶反応を伴う学習」を行う。
Feature Acquisition(特徴量の取得)
- learnerは初期モデルに問題がある場合(例:目的の精度を達成するために、あまりにも多くのサンプルを拒否する場合)、未知のクラスの存在を疑い、拡張する新しい特徴量を探索する。
- 具体的には、learnerは上述した以下の図において、K個の候補から最適な特徴量を選択し、拡張されたデータに基づきモデルを再学習する必要がある。
- 今回の中心となる問題は以下2つからなる
- 候補特徴量の品質をどのようにして測るか
- どのようにして、最適な特徴量を特定するように予算を配分するか
- 拡張されたデータを使ったモデルの再学習をどう行うか
Feature quality measure
特徴量の品質は、以下のリスク関数で定義される
Budget allocation strategy
Feature quality measureに基づき、最良の候補特徴量を特定するための予算配分戦略を考える。
- 以下の2つの選択肢を本論文では考えている(結果的に後者を採用している)
- Uniform Allocation(一律配分)
- Median Elimination(中央値消去):バンディットベース
Uniform Allocation(一律配分)
各候補特徴量 ) ]においてlearnerは[B/K]の予算を配分し、拡張データセット
を得る。
Median Elimination(中央値消去)
予算配分の効率を向上させるために、バンディット理論にインスパイアされた方法。 上記Uniform Allocationよりも効率的に最良の候補特徴量候補の探索が出来る。
本論文では、以下のようなバンディット理論のより洗練された技術の導入を行っているとのこと。

Model Cascade
特徴量を取得した後に、learnerは拡張したデータ上でモデルの再学習を行う。 予算が十分でない場合や、候補特徴量が十分な情報を持っていない場合、拡張したモデルが初期モデルよりも優れていない場合がある。 そのため、初期モデルに拡張モデルをカスケードするモデル構造を提案している。
- おおまかには以下のような構造になる。
- 信頼度の高い予測:初期モデルにacceptされる。
- 上記でacceptされなかった疑わしいサンプルは次の層に渡され、拡張サンプルで拡張モデルによって信頼度が高い予測が得られたものはacceptされる。
- 残りの疑わしいサンプルは更に改良するため次の層に進む。
Experiments
- 合成データおよび実データを用いて実験を行い、以下の観点から今回の手法を評価している。
- unknown unknownsを扱う上でのexploratory learning(探索的学習)の優位性
- 提案するExMLアプローチの有効性および特徴量獲得およびモデルカスケードの有用性
合成データ
- まず合成データを用いてExMLとSLを比較
- 合成データ(ground truth label):下図左
- 3次元特徴量
- クラス数3
- 各クラス数:100
- それぞれのクラスは3次元正規分布で生成
- 学習データ(known label):下図中央
- 3次元目の特徴量は隠している(2次元の特徴量を与える)
- クラス3をランダムにクラス1 or 2にラベル付けを行う

- 下図に結果が書かれている
- 下図左がSLを実施して2次元の学習データに基づいてreject modelを学習したもの
- 下図中央がExMLにより予算の範囲内で能動的に特徴量を拡張しunknown unknownsを発見したもの
- ExMLのほうがground truth labelをより分類できている(それはそうだろうと少し思う...)

実データ
UCI dataset Mfeatを用いて評価を実施している。
本評価においては、6つの特徴量群の内1つをオリジナル、残りを候補特徴量として様々な環境でアルゴリズムを比較している
アルゴリズム
探索的学習の有無、特徴量獲得アルゴリズムの種類、モデルカスケードの有無を比較するため、以下の4種類で評価
結果の解釈
- 表の上から3つまでの特徴量についてはそもそもオリジナルな特徴量のqualityが高いため、SLの精度は高くなる(本論文でターゲットとしているシチュエーションではない模様)
- それに対して、表の下の特徴量(情報量が少ない場合)では、SLの精度が劣化し予算の限られた中でもExMLが良い精度を出している事からアルゴリズムの有効性を主張している。

本論文では他のデータセットとして、RealDisp datasetでも評価を行っている(省略)
参考文献
Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection
Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection(AAAI2021accepted paperのArxiv)を読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
背景と概要
背景
- 電子商取引の爆発的な成長に伴い、オンライン取引の不正行為はそのプラットフォームにとって大きな問題となっている。
概要
本論文では、ユーザーの行動シーケンスに含まれる内部フィールド情報を、「フィールド値の変動」と「フィールドの相互作用」という2つの視点から利用するDual Importance aware Factorization Machines (DIFM)を提案している。
- 1つ目の視点:Field Value Variations Perspective
- 任意の2つのイベント間の各フィールドの値を補足(フィールドの特徴量はどの程度イベントで変動するか)し、フィールドのimportanceを認識する。
- 2つ目の視点:Field Interactions Perspective
- 各イベント内の全フィールド間の相互作用をモデル化し、イベントのimportanceを認識する。
- (フィールド:特徴量の事を示している。また特徴量の中で同じカテゴリ(IPやカード情報)に属するグループもフィールドとして本論文で表現されている。)
- (イベント:取引の単位)
- 1つ目の視点:Field Value Variations Perspective
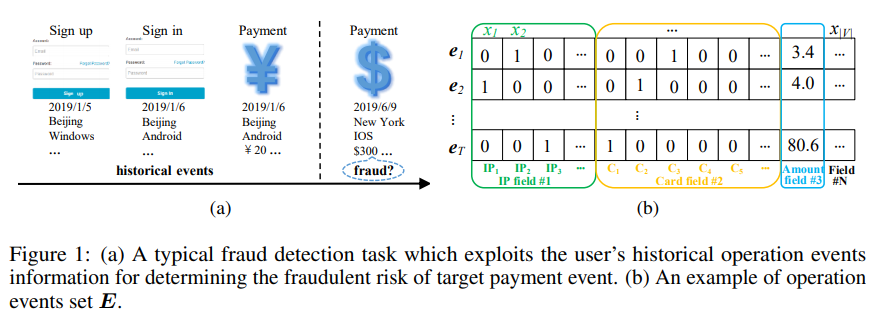
- 活用する情報としては、以下図のようなユーザーの過去のイベント(行動)を用いる
モデルの構造
- ベースのモデルとして以下2つがあげられている
- Factorization Machines(FM):特徴量は高次元で疎なデータなため、低次元で密なベクトル表現への埋め込みを行う(計算量の考慮あり)
- 以下2つのパターンでFMを計算
- 1つのフィールドに対してのイベント特徴量の埋め込み
- 1つのイベントに対してフィールドを埋め込み
- 以下2つのパターンでFMを計算
- Importance-aware Module(IM):フィールドやイベントの重要度を算出するため、Attentionに似た形の内積を計算。
- Factorization Machines(FM):特徴量は高次元で疎なデータなため、低次元で密なベクトル表現への埋め込みを行う(計算量の考慮あり)
- 上記を用いてイベントをまたいだフィールド値の変動およびフィールド間の相互作用を捕捉、これと予測したいイベントの情報を入力としてMLPで学習・予測する。

Methodology(以下詳細長め)
問題設定
ユーザーのoperation eventsの例として上図(b)を考える。
- 各イベントのフィールドは、IP fieldやcard field、payment amount field等で構成されており、それぞれのイベントにおいてフィールド数をNとする。
- それぞれのフィールドにおいて複数の値を持っていてもよい。
今回の予測におけるタスクは以下となる。
Factorization Machines and Importance-aware Module
- DIFMにはFactorization MachinesとImportance-aware Moduleという2つの基礎的なモジュールがある。
Factorization Machines(FM)
- 上図(b)にあるように、イベントの特徴量は高次元で疎なデータとなる。
FMはこのような問題に対処するために有効な手法であり、任意の2つのフィールド間の潜在的な関係性のモデリングを行っていると考えられる。
FMのプロセス
Importance-aware Module(IM)
- 不正検知では、異なるフィールド・イベントが異なる役割を果たす事が多く、その結果検知タスクにおいて異なる重要性を示すことがある。
- フィールドの重要性については、短期間でのIPアドレスや金額の変化が起こるフィールド(以上なフィールド)は、安定しているフィールドよりもリスクが高い事を示す傾向がある。
- そのためIP fieldやamount fieldこのようなパターンがある場合はより注意を払う必要がある。
- フィールドの重要性については、短期間でのIPアドレスや金額の変化が起こるフィールド(以上なフィールド)は、安定しているフィールドよりもリスクが高い事を示す傾向がある。
- 異なるフィールド・イベントの相対的な重要度の算出のため、Importance-aware(直訳:重要度認識) Module(IM)を設計
- 本Moduleは機械翻訳等において効果的である事がしられているself-attentionに似た形で設計している。
この式をAttention Is All You Needに記載のあるAttention構造と比較してみる。
要素1がと、要素2が
が対応しているので行列Vをかけている事以外はAttention構造と同じになっている。
Field Value Variations Perspective
- ハッキングされたアカウントの場合、実際のアカウント所有者の環境情報を模倣するのは非常にコストがかかるため、異なるイベントにおけるフィールド値の変動(例:IPが変わるなど)は、安定したフィールドよりもリスクが高い傾向にある。
- そこでfield value variations module FMを適用し、フィールド値の変動を捕捉する。
- n番目のフィールドである
について、全Tイベントにおけるフィールド値の変動を以下式と図の茶色のボックスのように実行する。
- n番目のフィールドである
- そこでfield value variations module FMを適用し、フィールド値の変動を捕捉する。

Field Interactions Perspective
不正検知では、ユーザーの不正行為は1つの特徴量を利用するよりも複数の特徴量を活用した方が発見しやすい。
- FMは任意の2つのフィールド値間のフィールド相互作用を実行しているが、全特徴量間の相互作用を単純に計算する事は非効率的。
各イベント内部のフィールドの相互作用を捕捉する。
- t番目のイベント
について、上図の青いボックスのように全フィールドでフィールド間の相互作用を計算する。
- t番目のイベント
DIFMアーキテクチャ
最終的なアーキテクチャは、上図(a)のように(7)のField Importance-aware Module、(9)のfield value variations、現在の予測イベントを組み合わせ ( ) MLPの入力とする。
Experiments
Datasets
- 今回は電子商取引プラットフォームにおけるカード(デビットかクレジット)取引のサンプルをデータセットとして使用
- データの特徴は以下
- C1,C2,C3の3つの異なる東南アジアの国における過去1か月間のイベント
- イベントのフィールド情報:IP、配送、請求、カード、アイテムカテゴリ、捜査結果、ユーザ
- アカウント、デバイス等の情報を利用
- タスク:支払いイベントがカードの盗難によるものかどうか
- データの統計情報は以下表となる。

Baselines
提案手法を特徴相互作用をベースとするモデル(以下W&D ~ xDeepFMまで)とイベントシーケンスをベースとするモデル(それ以外)で比較している。

アルゴリズムの設定
- 各種ハイパーパラメータ等は以下で設定されている
評価指標と結果
AUCを用いて各モデルの結果を評価している。
- 今回割愛しているが、各モデルの特徴を鑑みた評価も論文内に記述されていた。

各モデルのパフォーマンス
- 今回割愛しているが、各モデルの特徴を鑑みた評価も論文内に記述されていた。
また学習した重みよりハイリスク&ローリスクなフィールド値の一覧化も行っている。

予測結果の説明性について
- 学習した重要度に従い、以下図のように2つの不正行為のサンプルでリスクの高いフィールドおよびイベントの抽出を実施している。
- 図の説明
- 実線の丸:前回のイベントからフィールド値が変化している(図を見ると全部丸なので、全て変化していると理解している)
- 丸の中の色:具体的な記述が無いので推測だが、グレーの網掛けの場合フィールド内で複数の値がnon-zero
- 各マスの色:濃いほど重要度が高くなる
- 行われている結果の考察
- (1)のサンプル
- Card bin, IP ISP, Email suffix, Issuerフィールドは通常の利用者は安定しているが、このサンプルでは何度も変化しているためリスクが高い
- イベント2,4,5は以上フィールドの値が複数ある(重要度が高い所で網掛けの丸がいくつもある)ため、他の正常なイベントよりも重要度が高い
- 上記のような考察から、提供するモデルが説明可能な予測結果を提供する能力を持っていると論文で述べている。
- (1)のサンプル
参考文献
Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understandingを読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
背景と概要
BERT:Bidirectional Encoder Representations from Transformers
- 以前の言語表現モデルとは異なり、全層で左と右の両文脈に共同で条件付けを行う事で、ラベル付けされてないtextから深い双方向の表現を事前学習するように設計されている。
- その結果、事前学習されたBERTモデルに1つの追加出力層でfine-tuneをする事で幅広いタスクのためのモデル作成が出来る。
- BERTは大きく以下2ステップを主要なものとして構成
- pre-training
- fine-tuning
Introduction
- 言語モデルには事前学習された言語表現を下流のタスクに適用するために2種類の戦略が存在している。
- feature-based:ELMo等
- 事前学習された表現を追加の特徴として含むタスク固有のアーキテクチャを使用
- fine-tuning:GPT等
- 最小限のタスク固有のパラメータを導入し事前学習した全パラメータをfine-tuningする
- feature-based:ELMo等
本論文では上記技術では、特にfine-tuningアプローチのために事前学習された表現のパワーが制限されている事を主張している。
BERTでは、“masked language model” (MLM)のpre-training objective(事前学習の目的?)を使用する事で単一方向性制約を緩和する。
- masked language model:入力からトークンの一部をランダムにmaskし、文脈のみに基づいてmaskされた単語の基の語彙IDを予測する事を目的としている。
Related Work
Unsupervised Feature-based Approaches
- 広く適用可能な単語表現の学習は、非ニューラル(Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006)およびニューラル(Mikolov et al., 2013; Pennington et al., 2014)の手法を含め、数十年に渡って活発な研究が行われてきた。
- これらのアプローチは文の埋め込み (Kiros et al., 2015; Logeswaran and Lee, 2018)や段落の埋め込みs (Le and Mikolov, 2014)の様な粗い粒度にまで一般化されている。
- ELMo:従来の単語埋め込み研究を異なる次元(左から右へ、右から左への言語モデルから文脈に敏感な特徴を抽出)に一般化。
- 各トークンの文脈的表現は、左から右への表現と右から左への表現を連結
- Melamud et al. (2016)はLSTMを用いて、左右両方の文脈から単一の単語を予測するタスクを通じて文脈表現を学習。
- ELMoと同様に特徴ベースなので深い双方向性はない。
Unsupervised Fine-tuning Approaches
- 初期は特徴ベースのアプローチと同様にラベル付けの無いテキストから単語の埋め込みパラメータをfine-tuningしたもの。
- 最近では、文脈トークン表現を生成するsentence encodersやdocument encodersはラベル付けの無いテキストからpre-trainingされている。
BERT
BERTのフレームワークには2ステップ(pre-trainingとfine-tuning)がある。
- pre-training:違うpre-trainingタスクに渡りラベル付けの無いデータで訓練される。
- fine-tuning:BERTモデルが最初にpre-trainingされたパラメータで初期化されており、全パラメータはdownstream tasksからのラベル付きデータを使用してfine-tuningされる。
以下がBERTのpre-trainingとfine-tuning概要

Model Architecture
BERTのモデルアーキテクチャは、VaswaniらによるAttention is All you needに記載されているものをベースとした多層双方向Transformer encoder。
本論文では層数(即ちTransformer blocks)をL、隠れサイズをH、
self-attention headsの数をAとする。
そして主にBERT_BASE (L=12, H=768, A=12, Total Parameters=110M GPTと同じモデルサイズ)とBERT_LARGE (L=24, H=1024,
A=16, Total Parameters=340M)の2種類について記載。
Input/Output Representations
- BERTにおける入力表現は1トークン列の中で単一文(single sentence)と文(sentences)の組の両方を明確に表現可能。
- sentences:実際の言語文というよりは任意の連続したtextのspan
- sequence:BERTへのinput token sequence(single sentenceの場合や2つのsentencesをまとめた場合もある)
与えられたトークンについて入力表現は、対応するトークン・セグメント・位置embeddingsを合計する事で構築される。
以下図に本構造が示されている。

Pre-training BERT
BERTではpre-training時に2つの教師なしタスクを行っている。
Task #1: Masked LM
Task #2: Next Sentence Prediction (NSP)
- Question Answering (QA) やNatural Language Inference (NLI)といったタスクは2つの文の関係の理解に基づいており、言語モデルでは直接的に捉える事が出来ない。
Pre-training data
Fine-tuning BERT
BERTでは、self-atttentionを用いて連結したテキストペアをencodeする事により、文の間のbidirectional cross attentionを効果的に含む構造となっている。
各タスクにおいて、タスク固有の入力と出力をBERTにプラグインし、全パラメータをend-to-endでfine-tuneする。
- 入力においてpre-trainingからの文Aと文Bは以下の例に類似している。
- 言い換えにおける文ペア
- entailment(論理的含意、派生体)におけるhypothesis-premise(仮説-仮説?)ペア
- 質問と回答における質問-文ペア
- text classificationやsequence taggingにおける縮退したテキスト-∅ペア
Experiment
論文で言及されている実験結果の一部を記載
GLUE
The General Language Understanding Evaluation (GLUE)に適用した際の結果が以下
- BERT_BASEとBERT_LARGEの両方とも他の手法よりも大幅に上回っている。
- 特にBERT_LARGEでは訓練データが少ないタスクにおいて、BERT_BASEを上回っている。

SQuAD v1.1、SQuAD v2.0
The Stanford Question Answering Dataset (SQuAD v1.1およびv2.0)に適用した結果が以下。

参考文献
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/pdf/1810.04805.pdf
2020年度 仁科記念講演会
目次
講演
深層学習と物理学
講演目次
- 物理学から見る深層学習
- ニューラルネットワーク
- 深層学習
- 逆問題と物理学の革新
- 深層学習による物理学
- 物性物理学と深層学習
- 量子重力理論
- AdS/CFT対応と深層学習
逆問題と物理学の革新
- 関数y = f(x)についての問題とは?3種類ある
- 順問題:yが未知
- 逆問題1:xが未知→初期値問題(逆変換する方法がわかれば解ける)
- 逆問題2:fが未知→システム決定問題(厄介)
- 深層学習はシステム決定問題を問いている。(深層学習はfを求める)
- 逆問題は物理学の革新を導く
- 上から下に流れる
- 実験
- データ
- フィッティング←人間の直観によりモデルを考える(関数系を設定)
- 具体的関数
- 予言→実験へと進む
- 機械学習の位置づけは?
深層学習による物理学
物理学にも機械学習は多く使われている(e.g.天体の画像認識、素粒子実験等)
- 理論的な部分でどこに活用されているか?
物性物理学と深層学習
- 基底状態のためのアンザッツ
- 量子多体系でハミルトニアンが与えられた状態でシュレディンガー方程式を解く
量子重力理論
- ミクロの時空はネットワークである(時空はネットワークと解釈)
AdS/CFT対応と深層学習
- 時空をニューラルネットワークと見る
量子アニーリングによる量子コンピューティング
導入
-
- 離散多変数の1価関数を最小化(最大化)する問題
- イジング模型の基底状態を探す問題に帰着
組み合わせ最適化問題のイジング表現(流れ)
2値ペイントショップ問題
- ベルトコンベア上を多種類の車が2台ずつ流れてくるが、各車種を2色に塗り分ける
- 色の交代はコストがかかるので交代回数を最小化する
- 車の数が増えたり色の種類が増えるとNP困難な問題となる(実用上重要な問題)
- これをイジング模型で表現する
- VolkswagenがD-Waveの量子アニーリング装置で実証実験→288回の色変化が57回になった。(ただし古典コンピュータで出来ない計算かどうかは不明)
量子アニーリングの提案
最近の研究の方向性
- 量子シミュレーション:物理実験装置として使う
- 非断熱量子アニーリング(高速性、汎用性、古典シミュレーション不可能性):積極的に励起状態を使う
- 非疑似古典効果(高速性、汎用性):古典シミュレーション不可能な効果による量子加速
- 高度な量子効果(横磁場)制御:非一様磁場、逆アニーリング、一時停止による熱平衡化
現状と近未来
社会的な側面・まとめ
- 最大の課題は人材と基礎科学の研究
- 日本の最大の弱点は研究者層の薄さ。肌感だが米国と1桁違いそう
- 国内でこの分野を専門とする研究室は限られている
- 大学での組織的な人材育成への財政資源投入が、研究自体への予算配分より中長期的には有効かつ重要
- 基礎研究、デバイス作成、実証実験等あらゆるレベルの研究開発が同時進行
- 基礎研究がおわってから商品開発を進める通常の研究開発と全く異なる
数理最適化: Optimization Night #4に参加しました
「数理最適化: Optimization Night #4」に参加したので(オンライン)、まとめました。
間違っている箇所がある場合、指摘いただけると助かります。
目次
どんなイベント?
数理最適化に興味のある人達であつまって、わいわいがやがや議論する会です!
今回は、NTTデータ数理システムの大槻さんをお招きして、「動的計画法を活用した問題解決の概観」についてお話いただきます。 前回同様、後半の議論セッションで、お話いただいた内容をベースにみんなで議論できたらと思います。
発表
以下の2件の発表がありました 議論・Q&Aに関しては割愛します
動的計画法を活用した問題解決の概観
導入
数理最適化:与えられた制約条件下で目的関数の値を最適にする解を求める
動的計画法
動的計画法とは
- 問題を一連の部分問題に分割し、各部分問題の解をメモ化しながら順に求める手法
- 数多くの問題を分野横断的に解決できる
動的計画法による解法
- 問題を一連の部分問題に分割
- メモ化しながら、各部分問題の解を順に求める
- 汎用的で多くのパターンがある
着目する点:動的計画法の遷移パターン
- 漸化式と考えられ、その遷移パターンに着目すると、典型的なパターンをいくつか抽出できる
代表的な遷移パターン例
- ナップサック問題
- 解き方:全アイテムN個についていきなり考える訳ではなく、最初のi個のみを部分問題として考える(この際に重さも変数として加える)
- N個の要素をシーケンシャルに処理するDPとなる
- 似ている例:
- 隠れマルコフモデル(潜在変数が上記重さに該当)等
- 似ている例:
- 編集距離
- 文字列Sに変更・削除・挿入の操作を繰り返す事で対象の文字列Tに変換→その最小回数
- 2次元DPという観点だとナップサック問題と同じように見えるが、遷移図として表すと大きく異なる
- 二系列データの類似度を考える問題全般に適用される
- diffコマンド
- スペルチェッカー
- 音声、画像、空間認識(DPマッチング)
- バイオインフォマティクス(系列アラインメント:例2つのDNA配列の類似度)
- 区間分割
まとめ
- 動的計画法で解決できる問題のほとんどが共通の遷移パターンで扱える
- 共通の問題構造に着目することで明快に解ける
- 共通の理論と問題に特有の事情に分離することで、見通しの良い問題解決が出来る
ローカル線全駅下車の最適化
ローカル線の旅の難点:全駅下車して回ろうとすると時間がかかる→効率的に回る方法はないものか?
問題整理
- 目的
- 特定の路線の全駅を訪問
- 最初の出発駅・時刻を固定したうえで最終駅到着時刻を最も早くする
- 制約
- 最終的に出発駅に戻る
- 各駅で最低D分滞在
- 特別な制約の巡回セールスマン問題
解法
- 2ステップ
- 列車データを使いやすい形に変換
- 各駅のペアについて出発時刻をずらしつつ乗り換え検索を走らせる
- Bit DP
- 列車データを使いやすい形に変換
結果
- 人口データと実際のデータで検証
- 無駄な動きがあるので抑えたい
- 1日で回りきるのが不可能な場合の考慮も行いたい
Ultrafast Local Outlier Detection from a Data Stream with Stationary Region Skipping
Ultrafast Local Outlier Detection from a Data Stream with Stationary Region Skipping(KDD2020 Accepted Papers)を読んでまとめました。
長いので、背景と概要に中身を少しまとめています。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
背景と概要
- datastreamからのリアルタイムの外れ値検出がIoTの普及等により今後ますます重要な課題となっている。
- これに対処するため、いくつかの密度ベースのアルゴリズムが提案されているが、アプリケーションの性能要求を満たすのに十分な速度のものが無い実情がある。
- 本論文ではデータの分布がwindow slideを挟んでほとんど変化しない観測に基づいたアルゴリズムを採用。
- アルゴリズム概要
データポイントの偏り
実データはデータ空間内のいくつかの局所領域に偏っており、以下の図の様にデータ分布がある時間内でほぼ定常的となる場合がある。

Main idea
密度更新のスキップ
datastreamから局所的な外れ値検出を行うためにいくつかの密度ベースアルゴリズム(データポイントの密度を推定)があるが、既存のアルゴリズムでは密度の定常性を
無視しwindowがスライドする度にwindow内の全データ点の密度を更新している。
本論文では定常領域の密度更新をスキップしている。
- 以下の図においてa:前のwindow、b:密度のアップデート、c:現在のwindowを示している
- 前のwindowでは、x1・x3が外れ値となっている。
- 現在のwindowではx2が新しい外れ値となり、x3も外れ値となっている。
- 前と現在のwindow間でデータポイントの密度が変化するのは右側のみだが、既存アルゴリズムはbの上の様にglobalに更新する。
- 新しいアルゴリズムではbの下の様に左の静止領域をスキップし、残りの局所領域の密度のみを更新する。

スキップにおける課題
定常領域スキップの概念実装には以下2つの大きな課題がある。
- 1.データ点の密度変化を追跡することはデータ空間での度を実際に計算せず行う必要があり、コストがかかる。
- 2.定常領域をスキップしても、外れ値検出の精度が損なわれない必要がある。
本論文ではSTARE(local outlier detection by STAtionary REgion skipping)というアルゴリズムを提案。
STAREアルゴリズム
問題設定
- windowで分割されるdatstreamから密度ベースでtop-nのlocal outlier detactionを行う。
- windowがスライドするたびに、最も高いlocal outlier scoresを持つn個のlocal outliersを検出する。
アルゴリズム概要
- STAREアルゴリズムは、以下の図で示されているように3つのフェイズで構成されており、各windowでこれらを実行する。
- Data distribution update
- Stationary region skip
- Top-𝑛 outlier detection



フェイズ1:Data distribution update:
- 小領域を定義し、その中のデータ点の数をカウント。そのカウントを小領域のカーネル中心の重みとする。カーネル中心はデータ点の位置とは無関係に小領域の中心となる。
- データ空間を分割したグリッドセルを小領域とする。
- 前のwindowと新しいwindow間の各小領域のカウントの正味変化を前のwindowの重み分布に反映し効率的な重みの更新を行う。
- STAREでは
としてカウントの重み分布グリッドの正味変化を管理し、以下のアルゴリズムに示すようにwindowスライド間において
- STAREでは

フェイズ2:Stationary region skip
- 連続したwindow間の各小領域における重みの変化
のみで局所密度を更新する。
- 更に以下で表されるwindowに蓄積された誤差Eがある閾値
に達するまで局所密度の更新をスキップする。
本フェイズのアルゴリズム概要は以下で表されている。

フェイズ3:Top-𝑛 outlier detection
- データ点のlocal outlier scoresに基づいてn個のlocal outliersを検出する。
- 工程
- 全てのグリッドセルにおいて、local outlier scoreを更新
- スコアに基づいて候補グリッドセルを検出
- n個のlocal outliersを検出
以下式定義

結果
データセット
- 以下1つの合成データと5つのリアルデータで検証(データ詳細は論文参照ください)

アルゴリズム
- 以下5つのアルゴリズムで比較を行っている
- MiLOF
- DILOF
- sLOf
- KELOS
- STARE(本論文のアルゴリズム)
結果
- 他のアルゴリズムと比較し、計算時間や精度等優れている結果を示している。


