Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection
Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection(AAAI2021accepted paperのArxiv)を読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
背景と概要
背景
- 電子商取引の爆発的な成長に伴い、オンライン取引の不正行為はそのプラットフォームにとって大きな問題となっている。
概要
本論文では、ユーザーの行動シーケンスに含まれる内部フィールド情報を、「フィールド値の変動」と「フィールドの相互作用」という2つの視点から利用するDual Importance aware Factorization Machines (DIFM)を提案している。
- 1つ目の視点:Field Value Variations Perspective
- 任意の2つのイベント間の各フィールドの値を補足(フィールドの特徴量はどの程度イベントで変動するか)し、フィールドのimportanceを認識する。
- 2つ目の視点:Field Interactions Perspective
- 各イベント内の全フィールド間の相互作用をモデル化し、イベントのimportanceを認識する。
- (フィールド:特徴量の事を示している。また特徴量の中で同じカテゴリ(IPやカード情報)に属するグループもフィールドとして本論文で表現されている。)
- (イベント:取引の単位)
- 1つ目の視点:Field Value Variations Perspective
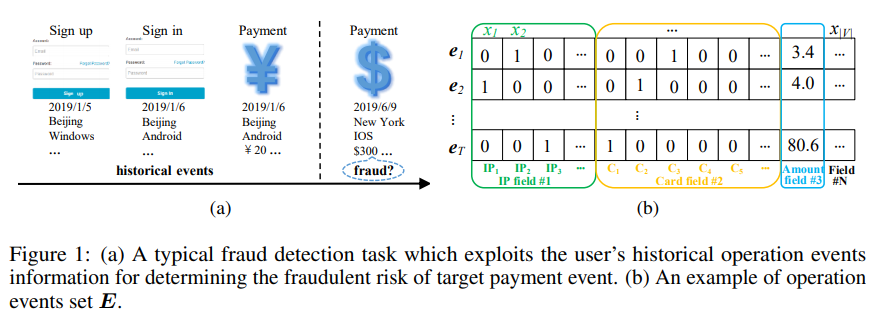
- 活用する情報としては、以下図のようなユーザーの過去のイベント(行動)を用いる
モデルの構造
- ベースのモデルとして以下2つがあげられている
- Factorization Machines(FM):特徴量は高次元で疎なデータなため、低次元で密なベクトル表現への埋め込みを行う(計算量の考慮あり)
- 以下2つのパターンでFMを計算
- 1つのフィールドに対してのイベント特徴量の埋め込み
- 1つのイベントに対してフィールドを埋め込み
- 以下2つのパターンでFMを計算
- Importance-aware Module(IM):フィールドやイベントの重要度を算出するため、Attentionに似た形の内積を計算。
- Factorization Machines(FM):特徴量は高次元で疎なデータなため、低次元で密なベクトル表現への埋め込みを行う(計算量の考慮あり)
- 上記を用いてイベントをまたいだフィールド値の変動およびフィールド間の相互作用を捕捉、これと予測したいイベントの情報を入力としてMLPで学習・予測する。

Methodology(以下詳細長め)
問題設定
ユーザーのoperation eventsの例として上図(b)を考える。
- 各イベントのフィールドは、IP fieldやcard field、payment amount field等で構成されており、それぞれのイベントにおいてフィールド数をNとする。
- それぞれのフィールドにおいて複数の値を持っていてもよい。
今回の予測におけるタスクは以下となる。
Factorization Machines and Importance-aware Module
- DIFMにはFactorization MachinesとImportance-aware Moduleという2つの基礎的なモジュールがある。
Factorization Machines(FM)
- 上図(b)にあるように、イベントの特徴量は高次元で疎なデータとなる。
FMはこのような問題に対処するために有効な手法であり、任意の2つのフィールド間の潜在的な関係性のモデリングを行っていると考えられる。
FMのプロセス
Importance-aware Module(IM)
- 不正検知では、異なるフィールド・イベントが異なる役割を果たす事が多く、その結果検知タスクにおいて異なる重要性を示すことがある。
- フィールドの重要性については、短期間でのIPアドレスや金額の変化が起こるフィールド(以上なフィールド)は、安定しているフィールドよりもリスクが高い事を示す傾向がある。
- そのためIP fieldやamount fieldこのようなパターンがある場合はより注意を払う必要がある。
- フィールドの重要性については、短期間でのIPアドレスや金額の変化が起こるフィールド(以上なフィールド)は、安定しているフィールドよりもリスクが高い事を示す傾向がある。
- 異なるフィールド・イベントの相対的な重要度の算出のため、Importance-aware(直訳:重要度認識) Module(IM)を設計
- 本Moduleは機械翻訳等において効果的である事がしられているself-attentionに似た形で設計している。
この式をAttention Is All You Needに記載のあるAttention構造と比較してみる。
要素1がと、要素2が
が対応しているので行列Vをかけている事以外はAttention構造と同じになっている。
Field Value Variations Perspective
- ハッキングされたアカウントの場合、実際のアカウント所有者の環境情報を模倣するのは非常にコストがかかるため、異なるイベントにおけるフィールド値の変動(例:IPが変わるなど)は、安定したフィールドよりもリスクが高い傾向にある。
- そこでfield value variations module FMを適用し、フィールド値の変動を捕捉する。
- n番目のフィールドである
について、全Tイベントにおけるフィールド値の変動を以下式と図の茶色のボックスのように実行する。
- n番目のフィールドである
- そこでfield value variations module FMを適用し、フィールド値の変動を捕捉する。

Field Interactions Perspective
不正検知では、ユーザーの不正行為は1つの特徴量を利用するよりも複数の特徴量を活用した方が発見しやすい。
- FMは任意の2つのフィールド値間のフィールド相互作用を実行しているが、全特徴量間の相互作用を単純に計算する事は非効率的。
各イベント内部のフィールドの相互作用を捕捉する。
- t番目のイベント
について、上図の青いボックスのように全フィールドでフィールド間の相互作用を計算する。
- t番目のイベント
DIFMアーキテクチャ
最終的なアーキテクチャは、上図(a)のように(7)のField Importance-aware Module、(9)のfield value variations、現在の予測イベントを組み合わせ ( ) MLPの入力とする。
Experiments
Datasets
- 今回は電子商取引プラットフォームにおけるカード(デビットかクレジット)取引のサンプルをデータセットとして使用
- データの特徴は以下
- C1,C2,C3の3つの異なる東南アジアの国における過去1か月間のイベント
- イベントのフィールド情報:IP、配送、請求、カード、アイテムカテゴリ、捜査結果、ユーザ
- アカウント、デバイス等の情報を利用
- タスク:支払いイベントがカードの盗難によるものかどうか
- データの統計情報は以下表となる。

Baselines
提案手法を特徴相互作用をベースとするモデル(以下W&D ~ xDeepFMまで)とイベントシーケンスをベースとするモデル(それ以外)で比較している。

アルゴリズムの設定
- 各種ハイパーパラメータ等は以下で設定されている
評価指標と結果
AUCを用いて各モデルの結果を評価している。
- 今回割愛しているが、各モデルの特徴を鑑みた評価も論文内に記述されていた。

各モデルのパフォーマンス
- 今回割愛しているが、各モデルの特徴を鑑みた評価も論文内に記述されていた。
また学習した重みよりハイリスク&ローリスクなフィールド値の一覧化も行っている。

予測結果の説明性について
- 学習した重要度に従い、以下図のように2つの不正行為のサンプルでリスクの高いフィールドおよびイベントの抽出を実施している。
- 図の説明
- 実線の丸:前回のイベントからフィールド値が変化している(図を見ると全部丸なので、全て変化していると理解している)
- 丸の中の色:具体的な記述が無いので推測だが、グレーの網掛けの場合フィールド内で複数の値がnon-zero
- 各マスの色:濃いほど重要度が高くなる
- 行われている結果の考察
- (1)のサンプル
- Card bin, IP ISP, Email suffix, Issuerフィールドは通常の利用者は安定しているが、このサンプルでは何度も変化しているためリスクが高い
- イベント2,4,5は以上フィールドの値が複数ある(重要度が高い所で網掛けの丸がいくつもある)ため、他の正常なイベントよりも重要度が高い
- 上記のような考察から、提供するモデルが説明可能な予測結果を提供する能力を持っていると論文で述べている。
- (1)のサンプル
参考文献
Modeling the Field Value Variations and Field Interactions Simultaneously for Fraud Detection