Delivery Scope: A New Way of Restaurant Retrieval For On-demand Food Delivery Service
Delivery Scope: A New Way of Restaurant Retrieval For On-demand Food Delivery Service(KDD2020 Accepted Papers)を読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
- 背景と概要
- 以下詳細(今回は長いです)
- delivery scope
- RESTAURANT RETRIEVAL SYSTEM ARCHITECTURE
- DELIVERY SCOPE GENERATION ALGORITHM
- 検証
背景と概要
背景
- 中国では、オンデマンドのフードデリバリーサービスが人気となっており、毎日3,000万件以上の注文がMeituan-Dianping(美団点評)の利用者により行われ、平均30分以内に配達されている
- Eater(食べる人、消費者)の急増と宅配業者の数が限られている事より、配送能力をどれだけフルに活用できるかがオンデマンドのフードデリバリーサービスのカギとなる。
概要
- 本フレームワークでは、delivery scope generation algorithmを提案している。
- delivery scope generation algorithmの流れ
1.ターゲットとなる飲食店のdelivery scope候補を作成。
- delivery scope候補作成の流れ
- 1.Initialization
- 2.Scope Shape Optimization for Experience
- 3.Scope Compression
- 4.Covering High-Demand Areas
- delivery scope候補作成の流れ
2.回帰モデルにより飲食店がscopeを採用した場合の注文数・平均の注文から配達までの時間を推定しスコアリング。
- 3.2値整数計画問題(binary integer programming problem)としてdelivery scopeの割り当てプロセスを定式化。
- 特定エリア内の各飲食店のdelivery scopeの最適化を行う。
- 近似解を高速に解くアルゴリズムとして、BIP Heuristic Algorithmを提案。
以下詳細(今回は長いです)
以下、フードデリバリーサービスの大きな流れ

delivery scope
- 制約:平均30分以内にEaterに注文を届けなければならないが、宅配の供給量に限りがあるので、Eaterが自分たちの町の全レストランに注文できるという状態は現実的ではない。
- サービスプラットフォームでは全レストランにサービスエリアとしてspatial polygon(直訳すると空間的な多角形)を提供している
- そのエリア内の飲食店にだけ、Eaterは注文が可能
- 本論文ではspatial polygon : delivery scopeと定義している。
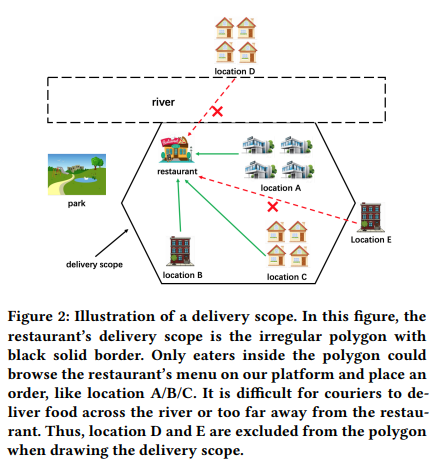
delivery scopeの従うべき原則
delivery scopeは以下の内容に従うべきである。
1.レストランの配達範囲は、需要の高いエリアをカバーしなければならない。
2.配達範囲は、その供給能力が相対的に低い場合、他のレストランより小さくなければならない。
3.配達範囲は、遠く離れた場所をカバーしてはならない。
RESTAURANT RETRIEVAL SYSTEM ARCHITECTURE
- レストラン検索システムについて:2つのpartで構成
- Delivery Scope Indexer
- delivery scopeの追加・削除などを実施
- Delivery Scope Generation System
- 後述
- Delivery Scope Indexer

DELIVERY SCOPE GENERATION ALGORITHM
- 目的:宅配業者による配達ブロックであるtarget station内の全飲食店に対して、リーズナブルなdelivery scopeを提供すること。
- 一つの駅にあるレストランの数:200~1000程
How to Draw Single Scope : delivery scope候補の生成プロセス
- delivery scopeは複数の頂点を持つ多角形で表現される。
- single scope generation algorithmは以下の4モジュールにより構成される。
- 1.Initialization
- 2.Scope Shape Optimization for Experience
- 3.Scope Compression
- 4.Covering High-Demand Areas
- 各モジュールはそれ以前の暫定delivery scopeを入力とする。
1.Initialization
- まずレストランの位置を中心として、入力半径(目標)の円を描く。
- 円:境界線上で等間隔の一定数の点で表現される。
- これらの点から中心までのnavigation distance(実際に到達するために移動する距離)が直線距離よりもはるかに大きい場合が考えられる。
- 本アルゴリズムでは、元の点と中心との間で中心までのnavigation distanceが目標半径にほぼ等しい点を探索(二値探索)。
- 各ステップにおいて、以下の長さで中心に向かい移動する。
- (小さい距離でも境界点を更新する毎に、navigation distanceが変化する事を想定していると思われる)
naviDist:境界点~中心のnavigation distance,
straightLineDist:境界点~中心の直線距離,
targetRadius:入力目標半径,
minStep:探索過程で最小移動長を制限するハイパーパラメータ

2.Scope Shape Optimization for Experience
- ユーザー、飲食店、配送業者のより良い体験を保証するためにdelivery scopeの境界線は道路に沿う必要がある。
- delivery scopeの境界線が建物やブロックに跨っている場合、同じ建物の中で異なるユーザー体験になる場合がある。
- e.g.同じ建物のEaterである飲食店に注文できる人・できない人が混在する場合があるかもしれない。
- delivery scopeの境界線が建物やブロックに跨っている場合、同じ建物の中で異なるユーザー体験になる場合がある。
- 道路に従った境界線取得のため、navigation routesを使用する。
- navigation routesを使用した際のstubを除去する処理も行われる。
3.Scope Compression
- 効率的なデータ計算のため冗長な点を除去する。
- 各点の隣接する点との角度を計算し十分180°に近い場合、その点は削除される。
- また隣接する点との角度および距離に基づいて各点を評価し、より高スコアな方を残す。
- 本モジュールには、Douglas-Peucker algorithmも用いられている。

4.Covering High-Demand Areas
- 需要の高いエリアをカバーするようにdelivery scopeを変更する。
- 中心を注文分布に応じてシフトさせる
- 需要の高い領域がdelivery scopeに直接マージされる。
- 上記領域はGeoHashクラスタリング(K-meansとDBSCANの組み合わせ)で決定される。

- 以下が実験で示されている実際のdelivery scopeの生成過程

Single Scope Scoring : delivery scope候補生成後のスコアリングプロセス
- 1つの飲食店に対し異なる半径のdelivery scope候補を生成した後、スコアリングを行う。
- 受注数の推定
- スコアリング対象のdelivery scopeの範囲が現状より小さい場合、過去の注文数を 用いる
- スコアリング対象が大きい場合、以下の2段階となる。
- 現状のdelivery scopeの範囲内(以下図の黄色い領域):過去データからスコアを計算
- 現状のdelivery scopeの範囲外かつスコアリング対象のscopeの範囲内(以下図のピンク色の領域):回帰モデルにて予測。
- リッジ回帰、ランダムフォレスト、XGBoost等を使用し比較している。
- 平均配送時間の推定:上記受注数と同様に計算される。

Delivery Scope Optimization
- ここまで得られた情報を使って、各飲食店に合理的なdelivery scopeを割り当てて駅におけるglobalな最適化(GMV (Global Merchandise Volume))や注文数を達成すると同時にEaterの体験を保証する事を考える。
問題設定
ターゲットとなる駅に対して以下を考える
今回の問題は以下のBIP(二値整数計画)問題として扱う。
上記問題の近似解を高速に解くアルゴリズムとして、以下のBIP Heuristic Algorithmが提案されている。

検証
A/Bテスト
- 1448駅、160,000の飲食店でランダムに選択しA/Bテストを実施
- 評価では以下の指標を使用している
- t:平均納品時間
- d:平均配送距離
- OR:オンタイム率
- CR:完了率
- CE:クーリエ効率、1人のクーリエ(配達員と同じ?)が1日に完了した注文数の平均
- 結果として以下を述べている(下の表)
- 注文数が約1.68pp改善
- クーリエ効率が約1.94pp改善
- また、下の図ではほとんどの実験都市では本論文で提案したアルゴリズムで生成したscopeの方が配送効率を悪化させずにより多くの注文をもたらしているとしている。


人が作った結果よりもアルゴリズムの結果が良い事に関する考察
- 以下の2点があげられている。
アルゴリズムで生成されたdelivery scopeは手動のものより優れている
- 人手で作った場合、境界点と飲食店の距離が同じになるような飲食店中心の多角形を描く傾向がある。
- そのためnavigation distanceと直線距離に大きな違いがあった場合、実質的にdelivery scopeが遠い位置をカバーする事となる。
BIPモデルがレストランの特性に応じて異なるscopeをカスタマイズしている。
- 一般的にconversion rateが高く、交通の便が良い程scopeを大きく設定できる。
- 以下の図は同じ駅の飲食店でも生成されるscopeに大きな違いがある事を示している。
Transformerの構造について調べてまとめた
Attention Is All You Needを中心として、Transformerの構造についてまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
概要
- 言語モデリングやシーケンスモデリングにおいて、RNN(特にLSTMやgated RNN)が主要なアルゴリズムとなっていた。
- RNNでの処理:前の隠れ状態
と位置tの入力の関数として、隠れ状態
を生成
- RNNのsequentialな性質により学習での並列化が出来ないため、シーケンス長が長くなるとバッチ処理が制限される(逐次計算の制約)事が課題となっていた。
- RNNでの処理:前の隠れ状態
- RNNを用いないシンプルなネットワークアーキテクチャとしてTransformerが提案された
- encoder-decoderモデル
- 以下の機構を持つ
- Self-Attention
- Multi-Head Attention
- Positional-Encoding
- データを逐次的に入力する機構を用いない事で、並列学習を可能としている。
Model Architecture
- encoder-decoder構造。
- encoder:入力sequence
を連続的表現のsequence
にマッピングする(入力の原言語をencodeする)。
- decoder:encoderの出力zを入力として、出力sequence
を生成する(目的言語の単語列を生成する)。
- encoder:入力sequence

Encoder and Decoder stacks
Encoder(上図の左側)
- N=6の同一層のstackで構成
- 各layer:2つのsub-layerで構成
- 1層目:multi-head self-attention mechanism
- 2層目:全結合のfeed-forward network
- sub-layer後に残差接続、layerの正規化を実行(上図のAdd&Norm)
- 各layer:2つのsub-layerで構成
- 各sub-layerの出力は、LayerNorm(x + SubLayer(x)) (SubLayer(x)はsub-layer自身が実装)
Decoder(上図の右側)
- Encoder同様N=6の同一層のstackで構成
- 各layer:3つのsub-layerで構成
- 1層目:マスキング付きmulti-head self-attention mechanism
- 2層目:原言語と目的言語間のmulti-head attention mechanism(Src-Target Attention)
- encoderの出力が入力となる。
- 3層目:全結合のfeed-forward network
- sub-layer後に残差接続、layerの正規化を実行するのはencoder同様
- 各layer:3つのsub-layerで構成
Attention
- Attention:一般的に入力データのうち、どの部分を重視するか決定する手段の総称。以下は論文においてて定義された内容。
- Attention関数は、3つの入力ベクトルであるクエリ(q)およびkey(k)とvalue(v)のペアのセットを出力にマッピングする。 以下はAttention構造を示している。

Scaled Dot-Product Attention(上図左)
入力:次元のクエリ(行列:Q)とkey(行列:K)、次元
のvalue(行列:V)で構成されているとする。
keyとクエリとの内積を計算し、各々をで割りsoftmax関数を適用しvalueの重みを求める。
実際の計算は以下となる。
Multi-Head Attention
- 単語間の関連の強さを考慮する機構
- 入力からQ,K,Vそれぞれを重み行列により
次元に線形写像し、h個の内積Attentionを計算。
- Self-Attentionでは直前の層の出力からQ,K,V全ての部分空間への射影を行っている
- 通常はクエリを別の情報源(入力)から用いる所を、self-attentionでは同一の情報源のみでAttentionを実施する。
- 同一文中で離れた単語の関係性が理解しやすくなる。
- decoderの2層目である(Src-Target Attention)では、Qがdecoderの直前の層の出力であり、KおよびVがencoderの出力となっている。
- Self-Attentionでは直前の層の出力からQ,K,V全ての部分空間への射影を行っている
- 本研究ではh=8の並行なattention layerを採用し、
としている。
Position-wise Feed-Forward Networks
- encoder-decoderの各レイヤには完全結合のfeed-forward networkが含まれている。
- そしてそれはReLUを挟んだ2つの線形変換で構成される。
Positional Encoding
- Transformerは再帰も畳み込みも含んでいない(入力を並列に処理する)。
- そのため、sequenceの順序を利用するためにsequence内のtokenの相対位置or絶対位置についての情報を入れる必要がある。
- そこでencoder、decoderのbottomにあるinput embeddingに絶対位置である「positional encoding」を追加する。
- positional encodingはembeddingとおなじd次元なため、両者の和を取ることが出来る。
- 本研究では、sin,cos関数を用いてpositional encodingを表現している。
- 以下の式で計算されたpositional encodingの行列を単語の埋め込み行列に可算したもの:encoder、decoderの入力となる。
参考文献
- Attention Is All You Need
https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
- Transformerによる時系列予測
https://www.jstage.jst.go.jp/article/pjsai/JSAI2020/0/JSAI2020_1N4GS1301/_pdf/-char/ja
- 英日翻訳タスクにおけるスワップモデルを通したseq2seqとTransformerの比較
https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P5-21.pdf
- 係り受け構造に基づくAttentionの制約を用いたNMT
https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/A1-4.pdf
- 係り受け構造に対する相対位置表現を考慮したNMT
https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P3-26.pdf
- 深層学習におけるアテンション技術の最新動向
https://www.journal.ieice.org/bin/pdf_link.php?fname=k101_6_591&lang=J&year=2018
ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networksを読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
概要
- 5つの畳み込み層(一部はmax-pooling層)と3つの完全に結合された層(計8つの学習層)で構成、overfittingを減らすためにdata augmentation, dropoutを採用
- CNNは同程度のサイズのfeedforward neural networkと比べてconnection・parameterが少ないので、訓練が容易でかつパフォーマンスは若干悪くなる程度。
- ネットワークの性能が、畳み込み層が削除された場合に低下する。深さが重要
architecture
- 以下が本アルゴリズムの構成

ReLU Nonlinearity
- 当時の予測モデルにおいては、
等が活性化関数として使われていた。
- 本論文では、活性化関数としてより高速になるReLU:max(0,x)が使われている。
- 勾配消失問題にも対応

ReLUとtanhの比較
Training on Multiple GPUs
- 本論文では2つのGPUにネットワークを分散させている。
Local Response Normalization
- 位置(x,y)でカーネルiにおいて活性化関数ReLUを適用して計算した値を
とすると応答正規化された値は以下となる
ここでの和は同一空間位置にあるn個の隣接するカーネルマップ(特徴
マップと同一?)で行う。
N:レイヤ内カーネル総数(カーネルサイズとストライドに依存?)
明るさの正規化に意味合いとして近い。
3.4 Overlapping Pooling
- CNNでのプーリング:隣接ニューロングループの出力を同一カーネルマップにまとめる。
- プーリングレイヤ:プーリングユニットの位置を中心としたz×zサイズの近傍を要約したsピクセル感覚のプーリングユニットのグリッドより構成。
- 従来:プーリングユニットはオーバーラップしない(s=z)
- 本論文ではs<z(s=2,z=3)としてオーバーラップさせている。
Overall Architecture
- レイヤー:全8層(最初の5層:畳み込み、残り3層:全結合)
- フィルタ
Reducing Overfitting
- Overfittingを防ぐために以下の2つの手法を使っている。
Data Augmentation
- 画像におけるOverfittingを減らす最も簡単で一般的な方法、ラベル保存変換を用いてデータセットを拡大すること。
- 2つの方法を採用している
- 画像の平行移動と対称移動
- 256×256pixelの画像からランダムに224×224のパッチを作り、その対称移動のパッチを作りそれらを学習に用いた
- RGBチャンネルの強度の変更
- ImageNetの学習セットのRGB画素値の集合にPCAを行う
- 画像の平行移動と対称移動
dropout
- 多くの異なるモデル予測の組み合わせはエラーの減少には有効だが、大規模なニューラルネットワークにはコストがかかりすぎる場合がある。
- そこで効率的な方法として、dropout(確率0.5で各隠れニューロンの出力を0に設定)を採用
結果
- ILSVRC-2010の結果

- ILSVRC-2012の結果

参考文献
Discovery DataScience Meet up (DsDS) #0に参加しました
「Discovery DataScience Meet up (DsDS) #0」に参加したので(オンライン)、まとめました。
間違っている箇所がある場合、指摘いただけると助かります(専門でない部分も多いため、間違っていたらすみません)
どんなイベント?
Yahooエンジニア, CAエンジニア, DeNAエンジニア, MoTエンジニア合同イベント! ScrambleTech19が主催している、データサイエンティストが日頃の業務で得た知見や悩みについて情報共有する会です! 「組織の枠を超えて、支えあえるDSコミュニティを創る」ことを目指しています!
今回は6名のLTから構成されていました。
LT
広告文自動生成プロダクトでDataflowを導入した話
- Dataflowをコピー生成プロダクトに導入した話
TensorflowのモデルをGCPでサービングしてきた話
- APIで予測結果をフロントに提供する必要がある→どのようにしてきたか?
SageMakerで試行錯誤する推論パイプライン
- 動画を入力とする推論パイプラインをSageMakerで作った話
- 当初のつらみ
- SageMaker導入
- 最初SageMaker Batch Transformで推論
- 感想
- Airflowの管理が面倒くさい
- 書き出し先のpathが分散しててイケてなかった
- Batch Transformへの書き換えが辛い(これが一番大きかったとのこと)
- Batch Transformのイケてない所があった
- 感想
- 修正事項
- 次にBatch Transformの代わりにProcessingを使う
- コードの修正は最小限になった
- スポットインスタンス未対応でコストがかかる
- 書き出し先pathをdag_idでまとめた
- 次にBatch Transformの代わりにProcessingを使う
- 最終構成
- Training jobで推論
- スポットインスタンス使える
- 未だ残るつらさ
- manifest fileがローカルモードに対応してない
- Training jobで推論
- 最初SageMaker Batch Transformで推論
Cloud Composerで組む機械学習パイプライン
- お客様探索ナビの機械学習パイプラインについて
- Cloud Composer
- ワークフローエンジン
- Airflowを採用
- タスクへの情報の渡し方
- Variable:Composer環境全体で共有される環境変数のようなもの
- XCom:動的な値を渡す(複数のdagでは参照できない)
- パイプラインを作っていく際
- GKEPodOperatorで全部やる
- PythonOperatorの制約等、Composer環境は複雑な処理に不向き
- 外部パッケージを良く使うような扱いでは、環境汚染が起きやすいPythonOperatorは向いてない
- PythonOperatorの制約等、Composer環境は複雑な処理に不向き
- GKEPodOperatorで全部やる
- まとめ
- Cloud Composerは構築・運用・実装がお手軽なワークフローエンジン
- 目標:MLリポジトリに変更があっても、パイプライン側は修正不要な状態が理想
- パイプラインはあくまでがわなので、実際の処理はGKEやAI Platformに全て任せる
- Composerの有効活用により、前処理からモデルの本番デプロイまで自動化と安定運用を実現できる
- Cloud Composer
検索システムのMLRモデル更新の自動化
- Solrのリランクプラグイン
- まとめ
- チーム内での検証が終わった段階でサービス導入はこれから
- A/Bテストやモデル選択も自動化したい
- モデル開発等にリソースを割くためにオペレーションコストを減らすのは大事
全社共通レコメンドプラットフォームへのKubernetes/Airflow導入
- 共通レコメンドプラットフォームを社内のKubernetes基板に移管
- プラットフォーム
- 専属のレコメンドチームを持たないサービス向けで様々なサービスが導入されている
- システム構成
- ETL・集計・学習を集約
- なぜAirflow?
- GUIで実行進捗管理出来る
- Kubernetesとの相性が良い→Kubernetes上で動的に学習リソース管理をしたい用途にマッチ
- Pipeline as Code
- Slack通知機能
- 効果
- DNN学習の運用改善
- DNNハイパラチューニングの定常稼働
- Airflowにおるworkflow管理の一元化・状況の可視化
- 現状の課題
- 特徴量管理
- サービス内の一部のログしか使えてない
- 実験管理
- kedro + MLFlow trackingに着目
- 監視
- オンライン性能の継続監視はまだ
- 特徴量管理
- プラットフォーム
Deep State Space Models for Time Series Forecasting
Deep State Space Models for Time Series Forecastingを読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
概要
- 状態空間モデルとディープラーニングを組み合わせた確率的時系列予測。
- 状態空間モデルに必要なデータの効率性や解釈性を維持しながら、深層学習により複雑なパターンを学習する。
- 共変量から状態空間モデルパラメータへのマッピングにRNN(LSTM)が使われている。
- 少ない学習データへの構造的仮定を組み込んだ対応から、大規模な時系列データから複雑なパターンを学習する事まで適用可能。
問題定義
- 確率予測問題を以下と定義
- N:一変量時系列集合とする。
この問題で解きたいのは、将来の軌道確率分布であり、以下で表される。
State Space Models
方程式
- 線形の状態遷移方程式となるモデルを考えると以下の式となる。
- また、一変量ガウス状態空間モデルとすると、以下となる
Parameter learning
- 状態空間モデルは、パラメータで完全に指定される。
- この論文では一般的なパラメータの推定方法として周辺尤度の最大化があげられている。
Deep State Space Models
学習
- 本アルゴリズムでは、各時系列毎に独立した状態空間パラメータ
を学習するのではなく、以下のmappingを学習する。
また、パラメータは以下の対数尤度関数を最大化する条件で推定される
- モデルの概観は以下となる。

Prediction
状態空間モデルから予測サンプルを生成するために、training rangeの最後のステップTの時点での隠れ状態を推定。
その後遷移方程式と観測方程式を再帰的に使い予測サンプルを生成する。
本論文ではカルマンフィルタの模様

結果
- 合成データを用いて検証する事で、データが生成された状態空間モデルのパラメータの復元が出来る事が示されている。

参考文献
https://pdfs.semanticscholar.org/7b8f/97663a190ddaf599f83d3ab6204639f8881a.pdf
Sports Analyst Meetup #8に参加しました
「Sports Analyst Meetup #8」に参加したので(オンライン)、まとめました。
間違っている箇所がある場合、指摘いただけると助かります。
どんなイベント?
スポーツアナリストおよびスポーツデータ分析に興味のある方に向けたイベントです。
本イベントはスポーツのジャンルを問わずスポーツアナリスト(を目指す人)にとって有益な.情報共有の場になることを目的としています。
今回は10名LTから構成されていました。
Zoomスポンサー枠
LT
サッカーがポーカーから学べるかもしれないNのこと
- ポーカーとサッカーの共通すること、それから学べるかもしれないことについて
- 対象とするポーカー:テキサスホールデム
- 意思決定
- 両者に不確実性がある
- サッカー:ボールを足で扱う、選手の振る舞いが不明
- ポーカー:不完全情報ゲーム
- 両者に不確実性がある
- 数学
- 期待値計算
- 共有カード
- ウェットやドライなボード
- 思考の自動化
- 情報戦
- 位置的優位性→情報を引き出す
- データ
感想
- 一見遠いと思える2つの領域で共通点を見出し、有効活用できる所に面白味を感じました。
- スポーツだけでなく、ほかの分野にも使えそうな発想だと思いました。
スポーツアナリティクスのオリジナリティを考える
- スポーツアナリティクスの独自性について
- 定義
- 当事者にとって科学(サイエンス)であること
- スポーツのパフォーマンス課題の構造化
- 要素:ゲーム構造、パフォーマンス結果・遂行・前提・リスク
- 当事者が求めているもの:科学的専門性からアドバイスがほしい
- スポーツのパフォーマンス課題の構造化
- アナリストにとって芸術(アート)であること
- 課題:する人と見る人である
- 背景:
- 楽しみたい→1人1人正解が違う→芸術(アート)
- 結果を出したい→共通した正解がある→科学(サイエンス):こちらに注目される事が多い
- 当事者にとって科学(サイエンス)であること
- スポーツアナリティクスは芸術と科学の要素を持つ
- 定義
感想
- サイエンスとは別の要素として、アートという表現が面白く言葉のニュアンスとしても非常にしっくりきました。
スポーツアナリストの現状と展望~現場で近いうちに必要になるであろうスキル~
- スポーツアナリストの現状
- 展望
- 営業マンはデータサイエンティストになれるのか→否
- スポーツアナリスト:メンターがいない、コーチへの「ステップ」的立ち位置
- これから
- スポーツアナリスト:現状維持
- データサイエンティスト:外から
- 近いうちに必要なもの(今やるべきこと)
- やがて来るデータサイエンティストに備えて、データを溜める基盤を作る
- アナリスト:ハブになっていく(ジェネラリストへ)
感想
- スポーツだけでなく、他の業界領域でも総合格闘技的な仕事になるのはあるあるだなと思いました。
集団スポーツの軌道予測
www.slideshare.net
- サッカーとバスケの選手軌道予測について
感想
- 予測誤差以外の指標を含める時に、どういう基準で採用するのかに興味があります。
- また弱教師情報を利用した手法にも興味があるので、調べてみたいと思いました。
Bリーグにおける勝敗とアリーナ集客分析
- スポーツビジネスで勝敗と集客の関連性があるのか?
- 仮説
- 勝てるチームの方が集客も出来る?
- 負けても集客できるチームがあれば集客の参考になる
- 分析結果
- 傾向:勝ち数が多い方が平均集客数も多い(但し大きな相関はない)
- 個々のチーム
- アルバルク東京(勝ち数多く集客少ない):最大収容人数も多くはないが、平均集客率90%→課題あり(立地も)
- 三遠ネオフェニックス(勝ち数少なく集客多い):スター選手によって集客が伸びている可能性がある
- まとめ
- 勝敗に依存しない集客は可能
- 立地やスター選手の獲得により影響がありそう
- 仮説
感想
- 室内競技であるバスケットボールでは当日の天気は集客に興味があるのか気になりました。
予想外に変化する投球の軌道は打者に学習されやすい?~Predictive Codingと予測誤差を添えて~
- 脳科学の枠組みで野球の投球を考える
- Predictive coding:入力の予測を行い予測誤差を最小化するよう学習する
- 野球において予測誤差があるシーン
- バッティングでの投球軌道の予測
- 誤差が大きい→失敗(空振り、凡退)
- 特異球(予測誤差の大きい)を定義
- 抑え投手が多い
- 仮定:特異球を武器にする先発投手は予測誤差が学習され徐々に打たれるのではないか?
- 特異球(予測誤差の大きい)を定義
- 誤差が大きい→失敗(空振り、凡退)
- バッティングでの投球軌道の予測
- 分析結果
- 1~3回:特異球投手が良いパフォーマンス
- 4~6回:非特異球投手が良いパフォーマンス
感想
- Predictive Codingについて初めて聞きましたが、他領域にも活用できそうで概要を調べてみたいと思いました。
無観客試合におけるホームアドバンテージ
- 無観客試合の結果を利用して、ホームアドバンテージの原因を考察
- ホームアドバンテージ:ある(Jリーグはマイルド)
- 想定される原因→無観客試合の結果がCrowd effectの証拠となるのではないか?
- Crowd effect(観客):最も明確かつ、ファンが支配的だと信じている
- 移動、環境への慣れ等
- 分析
- 対比較法
- 無観客と観客有りでホームアドバンテージに有意差があった(スペイン、ドイツが大きい)
- 他の要因(中断)が影響しているかもしれないので、調査対象を広げたい
感想
- 無観客試合によりホームアドバンテージに差があり、更にリーグごとに違う事が興味深かったです。
- リーグ毎に国が異なり、国土や移動距離も違うのが影響している可能性があるのかなと思いました。
アスリートのレーティングについて
- 個人スポーツ、団体スポーツにおけるアスリートのパフォーマンスのレーティングについて
- 活躍度の可視化
- 要素
- どの舞台で
- どの相手に
- どんな勝ち方
- 計算
- イロ・レーティングを用いた期待勝率計算
- チームスポーツ:個人とチームのものを組み合わせて計算
- 要素
- 活躍度の可視化
感想
- チームスポーツにおいて、レーティングにしやすいスポーツ、しにくいスポーツにはどういう要素があるのか気になりました。
サーブ制球力の定量的評価
- 定義:サーブのコントロールが良いor悪いとはどういうことなのか?
ライン際に集められているか否か→本当か?- ライン際に集める事はポイント獲得で重要なのか?→よりサーバー側が有利になる場所に集められているか?
- どこに集めると良いのか→機械学習を導入
感想
回転不足判定選手権をやってみた!
- 競技者(大学生)が回転不足判定を行った選手権について
- 回転不足について
- 点数:基礎点+出来栄え点
- 軽度回転不足、重度回転不足により点数が下がる→2点の中に4人入る等細かい差が勝敗にも大きく影響する
- 競技者が判定できているのか?→回転不足判定の選手権を実施
- 平均正解率:60.71
- 個人で視聴回数の違いで正解率に増減がみられる
- アンケートから競技者でも判定するのは難しい
- 選手の判定は実際の判定より甘め
- 回転不足について
感想
- 定量的に判別しづらいものは実際に競技をしている人でも判定が難しいのだなと思いました。野球のストライク・ボールの判定についても近い内容かもしれないと考えています。
最後に
- 様々な面白い話が聞けました、主催の皆様ありがとうございました。
Explainable k-Means and k-Medians Clustering
Explainable k-Means and k-Medians Clustering(ICML2020 Accepted paper)を読んでまとめました。
解釈間違い等ある時がありますので、その場合指摘いただけると助かります。
目次
背景と概要
- clusteringは幾何学データの教師なし学習の代表例だが、多くのclusteringアルゴリズムはデータの全特徴量に複雑に依存するため説明が困難
- 解釈性向上のため小さい決定木によるデータセットの分割を行った。→Explainable k-Means and k-Medians Clustering
- 教師なし決定木:Threshold treeと本論文では読んでいる
- アルゴリズム
- 通常のk-means clusteringとTree based clusteringの概観が以下のように示されている。
- 本論文では、このClusterの分割され方を以て説明性が上がったとしている。
- 図における✖印がmistakeと定義されている。この数を最小化する事も今回のアルゴリズムに含まれている。

k-means、k-median clustering
- k-meansとk-medianのゴール:与えられた集合
をk個の部分集合に分割してcluster中心までの点の距離を最小化
Explainable k-Means and k-Medians Clustering
- 以下の順番で記載
- threshold treesを使ったClustering
- k=2の場合のSingle Threshold Cutを用いたClustering
- k>2の場合のClustering:Iterative Mistake Minimization (IMM) algorithm
threshold treesを使ったClustering
- 2つのclusterを定義する最も単純な方法:1つの特徴量の閾値に基づいてデータを分割する事となる(Single Threshold Cut)。
- k>2の場合には、上記に閾値に基づいた分割(Binary Threshold Cut)を反復的に用いる。
- これらに基づいたk個の葉をもつthreshold treeによるk-medians、k-meansのコストは以下となる。
k=2の場合のSingle Threshold Cutを用いたClustering
- 2-meansの場合を考える。
- k=2の場合のコストは以下となる。
- 右辺第一項:1つ目のClusterについての計算、第二項:2つ目のClusterについての計算
k>2の場合のClustering:Iterative Mistake Minimization (IMM) algorithm
アルゴリズム
- 最初のステップ:k-meansやk-mediansといったアルゴリズムによるcluster centersを参照セットとする。
- 各データ点
に最も近いcluster centersのラベル
を割り当てる。
- 各データ点
- 以下がbuild tree procedureと呼んでいる決定木の構築ステップとなる。
- 以下が今回のアルゴリズムを示している。
